抖音大规模实践,火山引擎向量数据库对外开放服务
|
AI时代,如何用好大模型是当前各行各业瞩目的焦点。向量数据库作为大模型“记忆体”,不仅能够为其提供数据存储,而且能通过数据检索、分析让大模型进行知识增强,成为生成式AI应用开发新范式的重要组成部分。 用图片搜索图片或者文本搜索文本时,在数据库中存储和对比的并不是图片和视频片段,而是通过深度学习等算法将其提取出来的“特征”,“特征”提取的过程称为 Embedding,提取出的“特征”用数学中的向量来表示。向量化的目的是为了通过向量相似来进行非结构化数据的检索,向量化后的数据才能够被AI模型更好的理解使用。向量数据库就是用于生产、存储、索引和分析来自机器学习模型产生的海量向量数据的数据库系统。其典型应用场景比如:基于大语言模型的智能客服、基于企业知识库的问答以及Chatdoc等工具应用。 火山引擎向量数据库技术演进之路 ●存算分离的分布式架构搭建 在抖音集团内部,早期的向量化检索引擎是围绕搜索、推荐、广告业务来构建的,由于这些业务天然具有极大的数据规模,因此从一开始,就需要思考如何在向量索引中支持百亿数据的检索需求,比如图虫拥有几亿图片素材,数量规模早已超出单机内存的极限,举个例子,对于1亿条128维的Float向量,不考虑任何辅助结构,就需要100000000 * 128 * 4 bytes 也就是约48GB的服务器内存。 研发团队设计了一套存算分离的分布式系统架构,来进行向量数据的分片和分布式编排,通过向量存储、批式构建和实时在线检索,解决一份向量多个索引、支持多个场景的问题,同时,还能够节省索引构建资源,加快索引构建,使在线检索服务稳定性得到明显提升。对于用户来讲,在抖音上搜索内容则会又快又准。
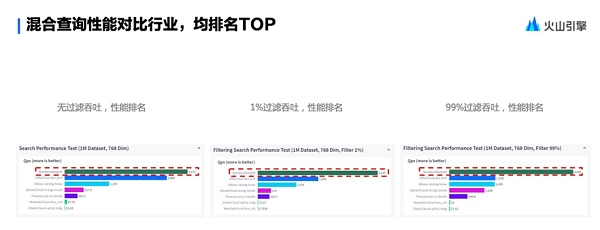
●计算内核性能优化 构建一个企业级的向量检索应用,数据量可能超过亿级,延迟在10ms内,要求用起来更快、更稳,所以在计算框架搭建好之后,也必须关注其内核,如何提供高性能的向量化检索服务以满足业务的苛刻需求。由于向量化检索是典型的计算密集、数据密集场景,其优化方向主要围绕提升吞吐、降低服务成本、提升稳定性开展。通过一系列性能优化工作,如降低内存占用、优化索引性能、CPU指令集计算优化、优化过滤和重排序等业务相关的计算过程,这套架构可以很好解决各类业务场景的离线和在线检索计算需求,相同检索精度下的吞吐和时延相比开源基线有了3倍以上的改善,且满足大规模线上业务的稳定性要求,因此被抖音集团大量业务采用。 但因为每个索引搭建一套集群的成本较高,且存在配置复杂等问题,研发团队又对框架进一步迭代,进行云原生改造,实现组件多租户化,提供自动化调度能力,以降低错误率,加快交付。 ●向量标量混合检索能力 向量数据库用于业务场景时,向量数据通常与结构化数据配合使用,例如,在将文档表示为向量的同时,还需要存储文档所属的部门,以方便在检索时进行权限过滤。这类需求可以抽象为使用与向量相关的结构化数据进行过滤,业界通常有两种解决方案:一是后过滤,将排名top的K个结果扩大一定倍数,检索出更多的向量,然后用结构化数据做过滤,留下topK个,这种方法适用于结构化过滤掉的比例较低,向量召回结果比例较高的场景;二是先过滤,先使用DSL过滤数据集,然后在结果集中进行向量排序,适用于DSL过滤结果较少的场景。 随着数据量的增加,这两种检索链路的性能各有适用的场景,但如何在执行时自动找到最适合的执行路径呢?为此,技术团队又研发了DSL定向引擎,支持在检索过程中同时进行向量检索和DSL过滤(结构化过滤),具有高性能、逻辑完备、可按需终止和执行计划优化等特点。在混合查询性能对比行业评测中,该向量数据库的无过滤吞吐、1%过滤吞吐和99%过滤吞吐多项性能均排名第一。
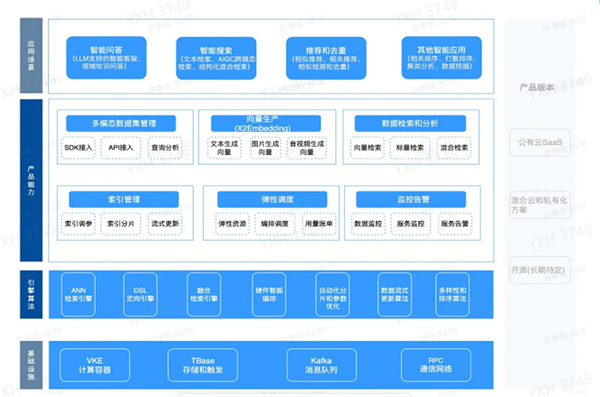
●帮助大模型知识库更快落地 大模型应用场景的不断拓宽,催生了向量数据的存储、检索需求。将企业自身数据转化为向量数据时遇到不少困难,如何帮助业务选择开箱即用的向量化模型,也影响到大模型应用的落地速度。技术团队在知识库、生成式AI素材管理等场景,开始尝试提供预设的向量化方法以供业务选择。大多数业务只需要选择一个适合自身数据的向量化方法,即可用原始数据直接写入向量数据库,并用相同的模型将请求数据转换为请求向量进行查询。 ●向量数据库技术全景 经过长期的内部探索和优化,抖音采用的向量数据库产品结构如下图所示:基于云基础设施,提供经过深度打磨和优化的各个引擎,提供从多模态数据写入,到向量生成,再到在线检索,以及上线后的弹性调度和监控的一整套全链路解决方案。
火山引擎向量数据库的场景化落地实践 经过抖音集团内部的技术实践,向量数据库目前已经覆盖50+的业务线,基本支撑了内部所有的向量检索场景,比如抖音、头条、懂车帝、图虫、火山引擎Oncall智能问答和剪映等,主要的业务场景包括智能搜索、AIGC跨模态检索、推荐和去重、智能问答、相关排序、聚类分析和数据挖掘等,并且多个场景库规模达百亿级别。 下面以图虫和火山引擎Oncall智能问答为例,展示向量数据库的应用实践。 ●智能搜索场景——图虫的以图搜图
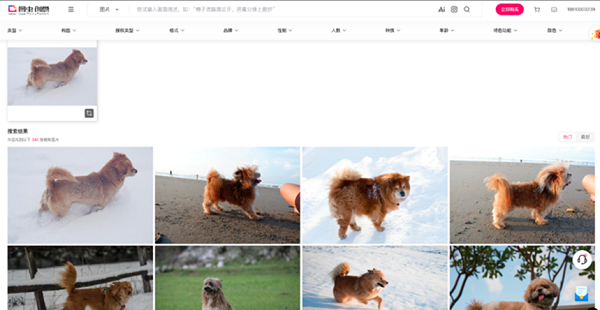
图虫提供了以图搜图的能力,致力于为用户提供正版素材内容及数字资产管理解决方案。目前,图虫创意在库图片量4.6亿、高清视频超2000万条,每天有大量用户来搜索、查询图片和视频。亿级海量数据对向量检索服务能力提出更高要求,业务如何灵活的设置分片,当数据量大幅增加时又如何避免重新部署集群,加快索引构建、节约资源。 解决方案是提供端到端的图片搜索能力,流程是先将图片源数据上传到向量数据库,把图片数据进行向量化、存储并形成向量索引,然后,用户将要搜索的图片上传,上传后向量化,向量化的图片与向量数据库进行向量检索比对查询,获取相似度最高的结果,返回给用户。 ●企业知识库场景——火山引擎Oncall智能问答
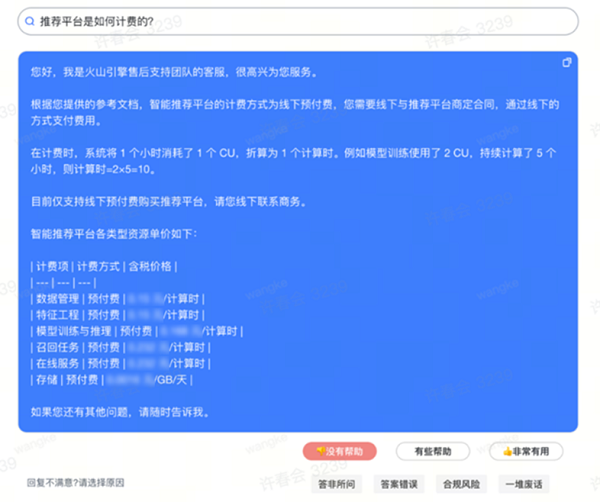
火山引擎Oncall智能问答能够辅助一线客服、提供客户问题回复参考。火山引擎官网每天会收到大量的客户售后进线,高峰时段人均要并行受理多个问题,需要能够快速排查并且给出客户反馈。对于工程师来讲,面对众多技术门槛较高的产品,要进行快速理解和判断,难度较大。 解决方案就是,将火山知识库文档和数据通过向量特征提取,然后存储到向量数据库中,应用LLM大语言模型与向量化的知识库检索和比对知识,构建火山引擎Oncall智能问答,可以让聊天机器人的回答更具专业性和时效性,构建专属Chatbot。未来,火山引擎Oncall的FAQ知识将持续沉淀,知识库持续完善,同时还能提供大模型训练数据,处理大量客户咨询问题,实现机器人自动生成回复结果。 如今,向量数据库已经成为整个大模型生态的基础设施,支撑着大模型在业界的推广和应用。火山引擎向量数据库技术经过抖音等业务的实践打磨,已经对外开放,赋能千行百业,加速AI大模型落地应用。未来随着新的应用场景的出现,向量数据库还将持续创新,提供更加灵活和多样化的功能,满足不同用户的需求。(作者:程峻熙) |