StreamingLLM框架亮相:突破文本长度限制
|
10月06日消息,麻省理工学院与meta AI的研究人员最近宣布他们成功开发了一项名为StreamingLLM的创新框架,该框架被认为能够解决大型语言模型面临的内存和泛化问题,使其能够轻松处理无限长度的文本内容。
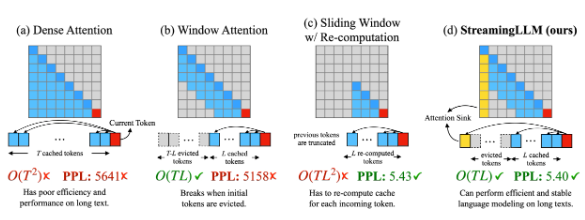
这一研究的关键焦点在于克服实现高效流式语言模型(Efficient Streaming Language Models,ESLM)时所面临的障碍,尤其是在长时间多轮对话等场景下可能出现的问题。 据本站了解,研究人员指出,构建流式语言模型主要面临两大挑战。解码阶段获取标记(token)的键(Key)和值(Value)状态会耗费大量内存。其次,现有的大型语言模型很难泛化到处理超出其训练序列长度的长文本。 过去的研究尝试解决这些挑战,例如扩展注意力窗口以处理长文本或建立一个固定大小的活动窗口,只关注最近的标记状态以维护内存使用和解码速度。然而,这些策略在处理超出缓存大小的序列时表现不佳。
StreamingLLM采用了一种名为"注意力下沉"的策略,通过观察到自回归语言模型中,某些标记会获得大量的注意力,即使它们在语义上并不重要,这些标记也会吸引模型的关注。这种策略确保了无论输入序列的长度如何,模型的注意力计算都能保持稳定。 StreamingLLM的重要贡献在于提供了一种简单而高效的解决方案,使语言模型能够处理无限长度的文本,而无需进行微调。这将有助于解决当前流式应用中语言模型面临的问题。虽然流式语言模型在未来将变得更加重要,但由于内存效率和长序列处理性能等方面的限制,相关模型的发展仍面临挑战。 据研究团队验证,StreamingLLM能够使Llama 2、MPT、Falcon和Pythia等模型可靠地处理长达400万个标记的文本,从而为流式语言模型的部署提供了更多可能性。这一创新有望推动自然语言处理领域的发展,并为各种应用场景带来更强大的语言模型支持。 |